AutoBench for corporate LLMs Integration
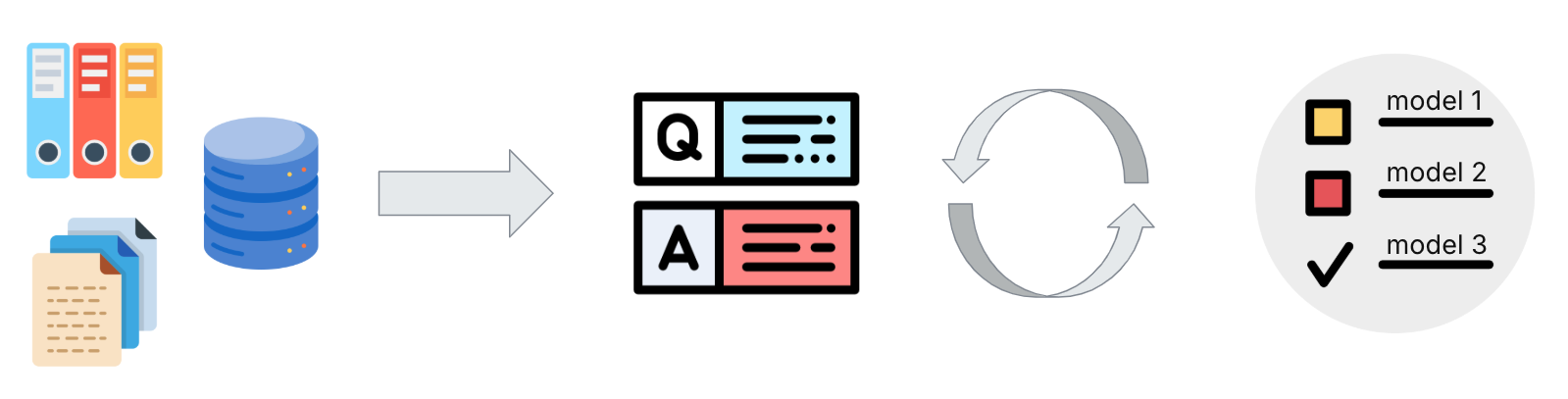
This project focuses on developing an automated solution to evaluate the performance of large language models (LLMs) on proprietary corporate data.
The system benchmarks multiple LLMs using predefined tasks and metrics, generating insights into their accuracy, efficiency, and suitability for enterprise use cases. The outcome helps organizations determine which LLMs are best aligned with their data, compliance needs, and operational goals.
Solving practical problems for:
Standardized Performance Comparison
Enabled objective evaluation of multiple models using the same metrics and tasks
Enterprise Suitability Insights
Identified which LLMs align best with internal data and operational goals
Compliance-Aware Evaluation
Incorporated data privacy and regulatory needs into the model selection process
Actionable Recommendations
Provided decision-makers with clear guidance on LLM adoption based on real benchmarks